

Episode I: Attack of the Code Editor Clones
AI Code Editors have the same bold promises as the neobank fintechs of yesteryear, but without factoring in unit economics, we’re due for the same harsh realities.

This deep dive is part of a three part series on the cost of compute and the economics of AI infrastructure that will be released over the next three weeks.
The Price of Intelligence Saga:
Episode I: Attack of the Code Editor Clones:
AI Code Editors have the same bold promises as the neobank fintechs of yesteryear, but without factoring in unit economics, we’re due for the same harsh realities.
Episode II: The Token Economics Strike Back:
The math of compute breaks down when we break down the price of the prompt and the token taxes for AI code editing
Episode III: The Hyperscaler Menace:
The unsustainable economics problem goes deeper than the code editors, down to the looming crisis of the AI infrastructure that powers the entire ecosystem
In late 2021-2022, the fintech scene exploded with a surge of neobanks for every affinity and demographic. They quickly amassed users, deposits, and purchase volume to excite any VC. But everyone seemed to forget that with fintech, unlike SaaS, just getting PMF isn't enough because the costs to serve are real and significant. If pricing isn't right, you're just selling a dollar for $0.50 and your users are taking advantage of you.
Cracks appeared in the ecosystem as bank platform fees, processor costs, and compliance expenses caught up to them. Today, we only see the remnants of many sought-after neobanks.

Today, the same pattern is playing out in AI coding tools, but with a greater disconnect between growth and unit economics. Fintech companies assumed they could acquire users for free and monetize them later, and AI code editor companies assumed they could get developers hooked on unprofitable $20/month tools and either rate-limit them into higher tiers or upsell them to enterprise. Both assumptions share the same fatal flaw - users adopted the products because it was a great deal.
The killer feature was the unsustainable pricing, and we’ll soon find out what happens when you take that away.
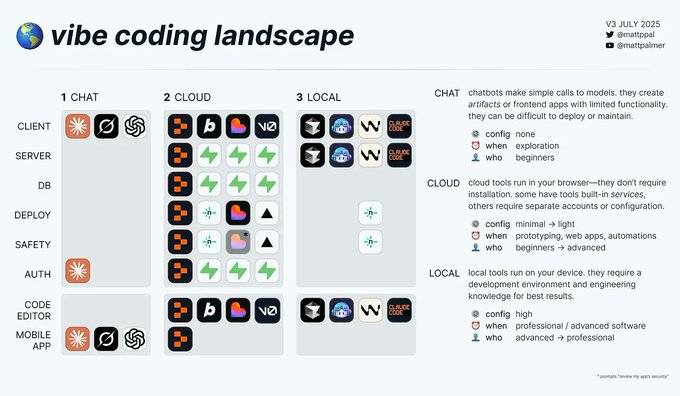
The Rise of AI Code Editors
As ChatGPT unleashed a new paradigm of AI interaction, a wave of AI-powered code editors emerged promising to transform how developers write code. These weren't just autocomplete tools; they promised to be integrated development environments (IDEs) and pair programmers that could understand context, explain complex code, debug issues, and write entire functions from natural language descriptions.
Source: Matt Palmer, Replit
The pitch was compelling. It promised “10x developer productivity” through AI assistance handling documentation to debugging. Companies like <u>Cursor</u>, <u>Windsurf</u>, <u>Replit</u>, <u>v0</u>, Convex Chef, <u>Bolt,</u> and Lovable offered seamless integration, context-aware suggestions, and natural language interaction with codebases. The future of development, they claimed, would be a collaborative vibe between human creativity and AI capability. By mid 2025, every company from Airtable to Figma was integrating “vibe coding” into their platform and every post mentioned it.
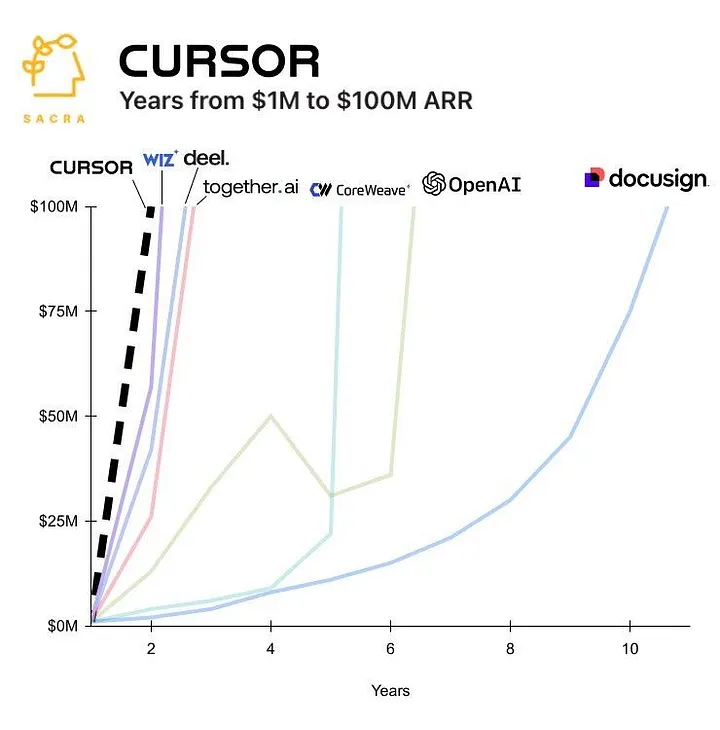
Within months, the numbers became staggering. Lovable crossed $75M in a 12 months. Windsurf at $100M in 18. Cursor hit $500M ARR in under 3 years. These represented some of the fastest companies to reach $100M ARR in history, outpacing success stories like Wiz and Deel.
Source: Sacra
The playbook seemed perfect. Small, lean teams built AI-powered developer tools that could scale infinitely. Cursor reached $100M ARR with just 20 employees, while Windsurf added $2M in new ARR monthly with a team of 15. This leverage was unprecedented - traditional enterprise software companies needed 5-10x more people for similar growth.
VCs couldn't write checks quickly enough. In two years, Cursor raised $500M at a $10B valuation. Windsurf commanded a $3B valuation before acquisition rumors began swirling. Lovable's rapid rise saw them raise a $200M Series A at a $1.8B valuation 8 months after launching, and Replit reached $3B.
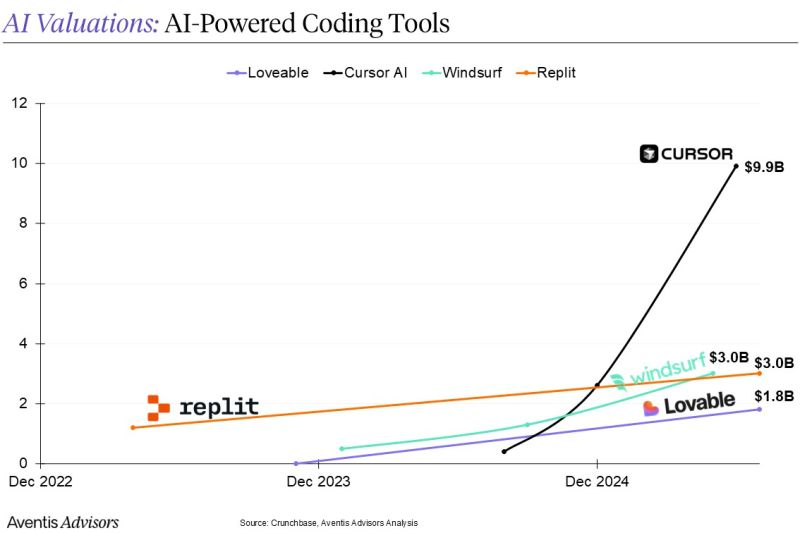
Source: Aventis Advisors
Beneath the surface, a fundamental problem was brewing. The same $20/month "all you can eat" pricing driving this explosive growth masked unsustainable unit economics. Like the neobanks before them, these companies confused price-driven adoption with product-market fit. The assumption was classic SaaS playbook; land users cheaply, then expand through usage limits or enterprise upsell.
This would have worked if they sold high-margin software, but they weren't. They were selling compute, which is more expensive than anyone realized.
Too Many Tokens for Your Thoughts
These companies are selling compute for less than its cost, hoping usage patterns or future efficiencies will help. After an over-engineered deep dive to understand the economics of a code editor (read more in Episode II), the reality became clear; the token unit economics don’t compute.
To understand the unit economics, we focus on the basic unit, the "token." Tokens are the basic units of text that AI models process - they can be chunks of words or parts of words. A token might be a common word like "the," part of a longer word like "comput" in "computing," or a single character. When AI processes text, it breaks it down into tokens, and each requires computational power. The more tokens processed, the higher the computing costs. Even a simple styling change leads to a cascade of AI actions that consume tokens and increase costs.

Replit “effort-based pricing” pricing rationale
A thirty-five token prompt set off a chain reaction inside the AI's brain. First, it read 822 lines of context, then processed it 14 times. It planned, reasoned, generated explanations, and made changes. By the time it finished this supposedly "simple" task, the AI churned through 18,395 tokens of computational power.
At current market rates, this cost the platform $0.62 in raw compute costs. They charged $0.22 for the interaction. That's a 64% loss on every similar request. Even "quick" questions burn through 7,000+ tokens, while debugging sessions can exceed 23,000.
Remember how neobanks discovered they were selling dollars for fifty cents? AI code editors are doing the same thing - faster and at a greater loss. The math reveals an uncomfortable truth: these companies aren't just unprofitable; they're selling compute power at a significant loss, and no clever pricing can fix this fundamental economic problem.
In fact, this problem is worsening due to Jevon's Paradox manifesting in two ways:
First, our expectations of AI capabilities keep expanding. What started as quick responses to coding questions has evolved into multi-minute sessions with thousands of tokens of code changes and detailed explanations. The "magic moment" bar keeps rising.
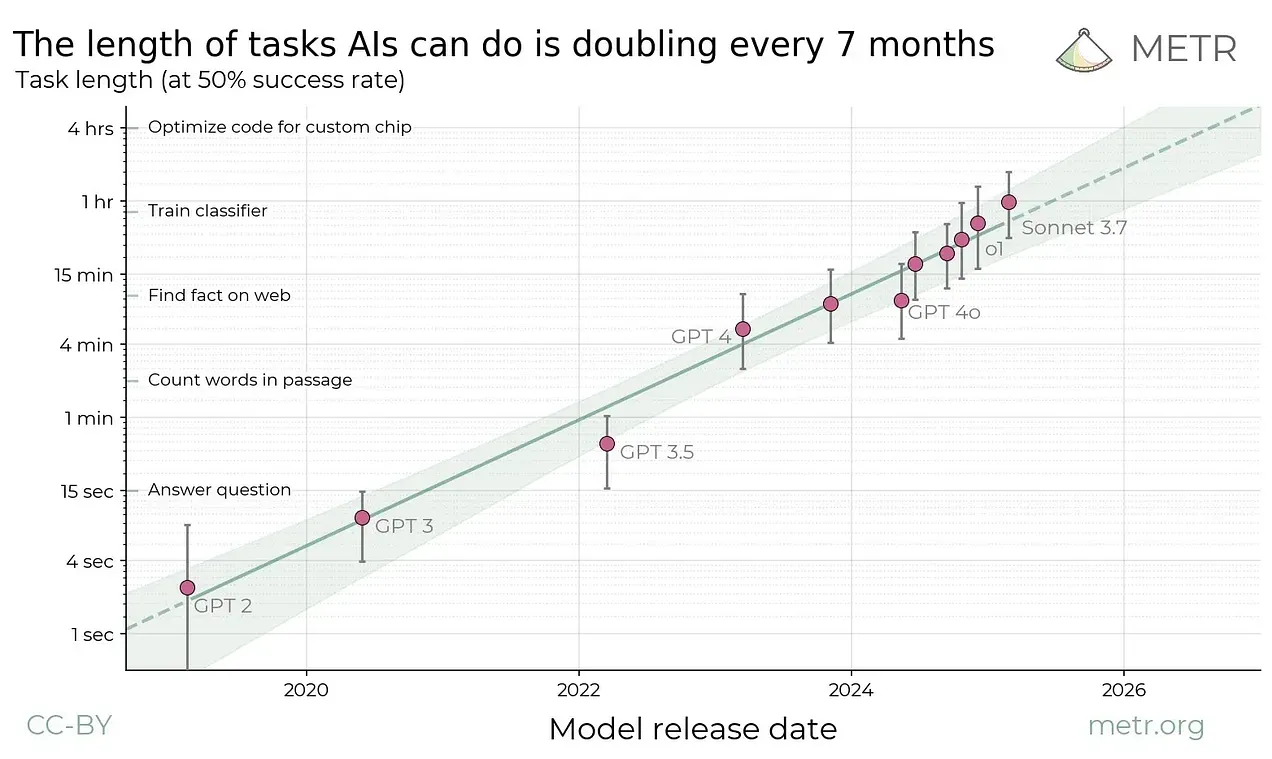
Source: Metr
Second, while compute costs for older models are decreasing, users demand access to the newest, most capable ones regardless of cost. Ethan Ding's analysis of AI economics notes, "Tasks that returned 1,000 tokens in 2023 now generate 100,000+” - a 100x usage increase driven by expanded expectations and more sophisticated model responses.
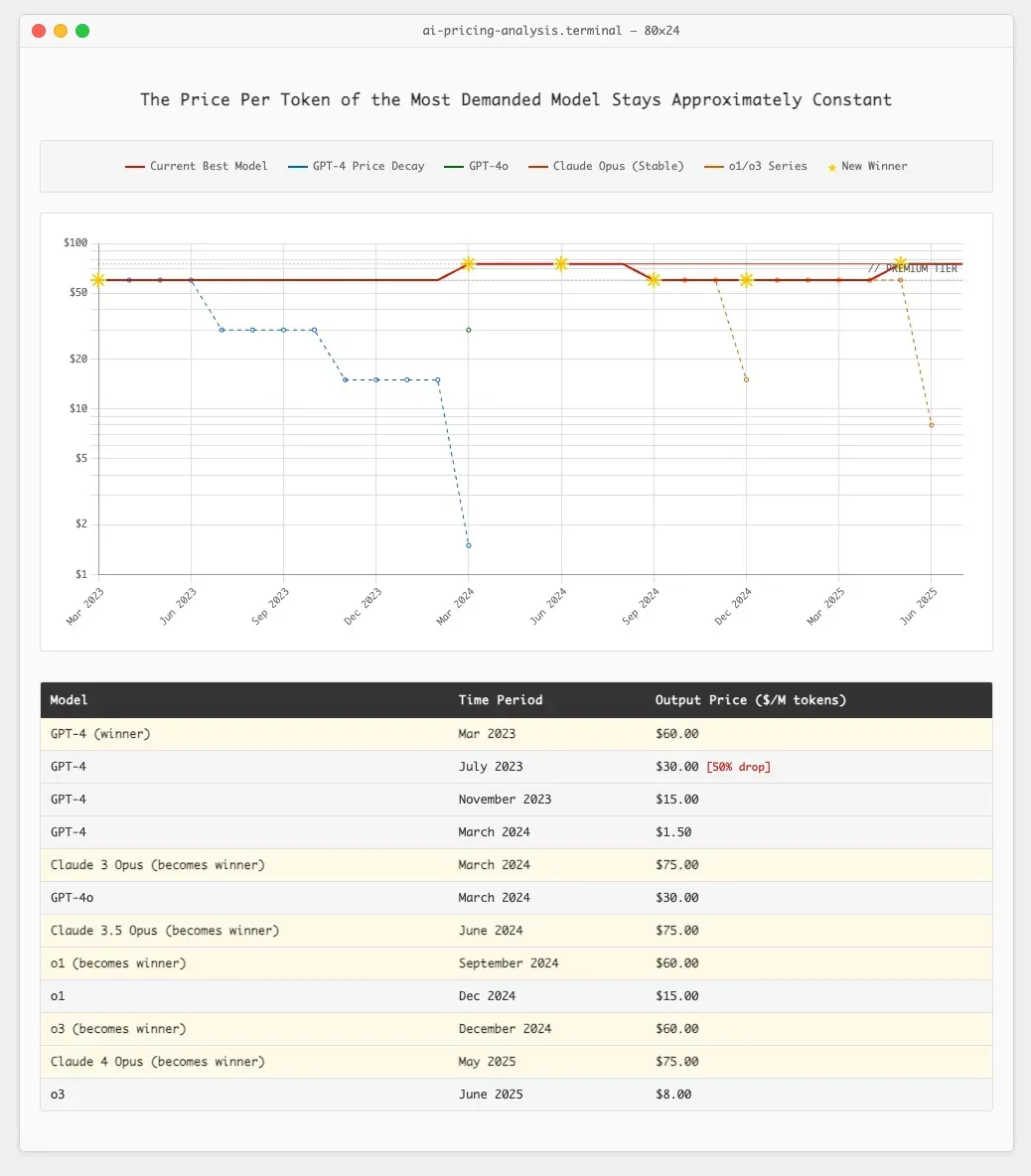
Source: Ethan Ding
Remember the viral tweet about AI startup math? He was joking, but the reality reveals something more fundamental. We've built an entire market on the assumption that AI-powered development would follow traditional SaaS economics, which is colliding with the hard reality of compute costs.
The Pricing Model Evolution Crisis
As token costs became clear, companies scrambled to evolve their pricing models. Each iteration revealed the complexity of the unit economics problem and our misunderstanding of AI-powered development.
Phase 1: The $20 All-You-Can-Eat Disaster (2023-early 2024)
Most started with the same playbook: $20/month for unlimited AI assistance. It was a common growth strategy - acquire users now, figure out monetization later. The strategy worked in one sense. Companies like Cursor and Windsurf reached $100M ARR at record pace. But they were effectively paying users to use their product.
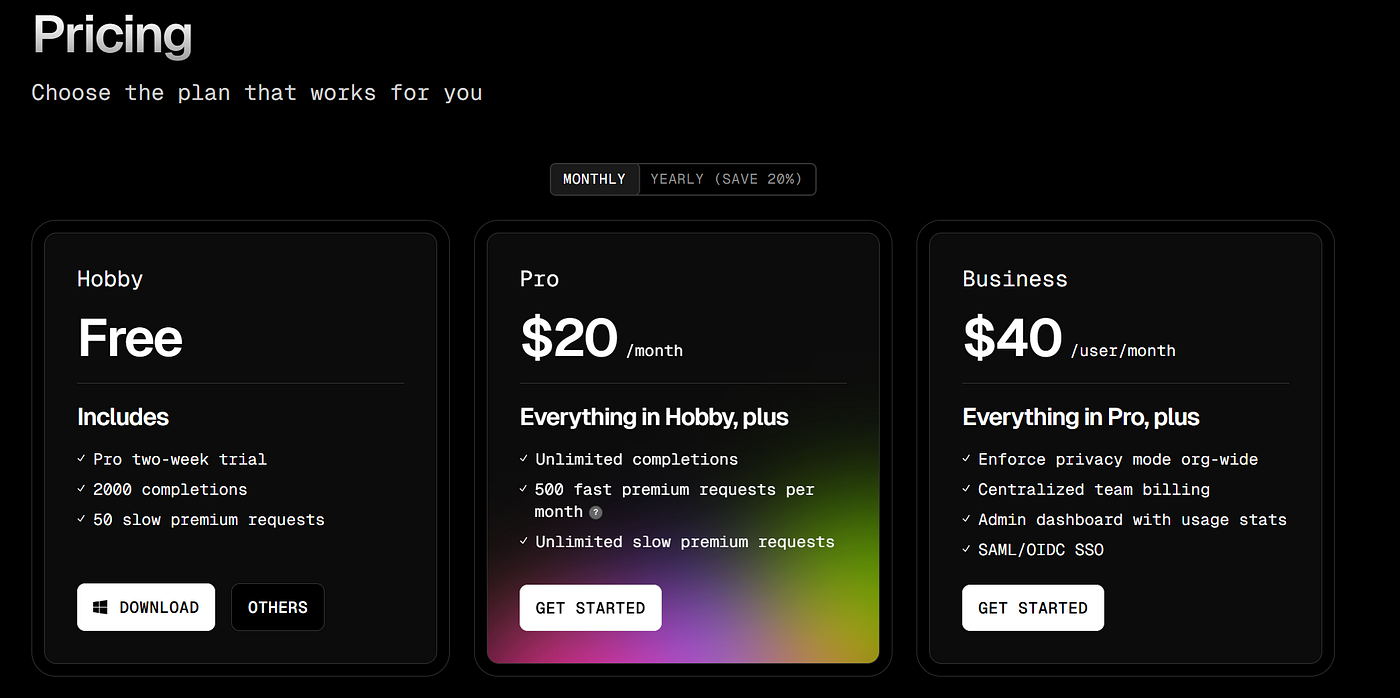
Power users exploited this model, consuming 100x the average usage while paying the same flat fee. GitHub’s $20/month Copilot was losing Microsoft $20 per user/month, before reasoning, increased context windows, and vibe code editing came into play.
Phase 2: The Query-Limited Scramble (mid-2024 - mid-2025)
By late 2024, the economics became impossible to ignore. Monthly compute costs per user were skyrocketing and companies faced a difficult choice: raise prices or limit usage, either of which could cause user exodus. Most chose the latter, leading to an era of complex usage restrictions.
Cursor moved to a complex token-based credit system, where different actions cost different amounts. But users revolted en masse at the new pricing that led to escalating costs, leading to a public apology from the CEO.
Many users said they ran out of requests in Cursor rather quickly under the new plan, in some cases <u>after just a few prompts when using Anthropic’s new Claude models</u>, which are particularly popular for coding. Other users claimed they were <u>unexpectedly charged additional costs</u>, not fully understanding they’d be charged extra if they ran over the $20 usage limit and had not set a spend limit. In the new plan, only Cursor’s “auto mode,” which routes to AI models based on capacity, offers unlimited usage for Pro users.
TechCrunch
Windsurf tried limiting queries, offering "$20 for X queries/month." It was the desperate math of a company realizing its fundamental assumptions were wrong. For what it's worth, Windsurf prices API calls at 20% above the API price at $0.04 (which also means max 17% margins). Their plan pricing of 2,000 prompts for $15 equates to $0.0075 per prompt, costing 0.25 credits, which means $0.03 per credit. So the plan pricing is cheaper than the API pricing? They don't seem to be very good at math.
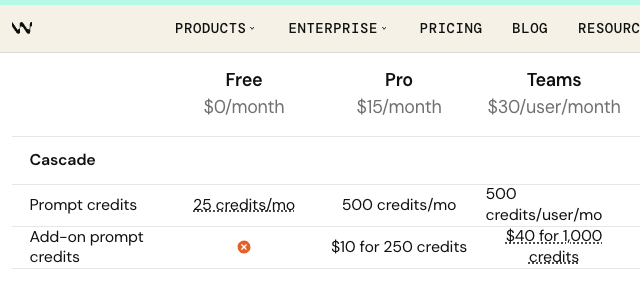
Source: Windsurf
Phase 3: Effort-Based Pricing Doesn’t Capture Full Effort (mid 2025 to present)
Replit took a fundamentally different approach while others scrambled with query limits and credit systems. They understood that the only sustainable path was to align pricing with computational costs. The result was effort-based pricing - a sophisticated attempt to match user charges with the actual work performed.
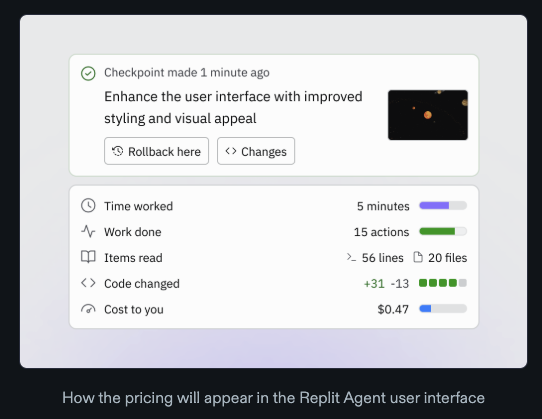
Source: Replit
Replit's effort-based pricing aligns costs with usage. They charge based on actual computational work: time spent, actions taken, lines read and changed. It's transparent, fair, and a genuine attempt to match pricing to compute costs.
But here’s the problem: we used Replit’s effort-based pricing model for our cost analysis. Even with the best pricing approach, changing a box shadow color costs $0.62 in compute but generates only $0.22 in revenue. The advanced pricing model still results in ~64% losses on nearly every interaction. Something doesn’t compute. (Note: I used Claude’s pricing for the analysis, the most expensive but the de facto for code editors, so Replit might use cheaper models to make the economics work).
Unfortunately, the company's margins, which should tell the clearest story, are clouded by creative accounting. Companies report 23% to 60% gross margins, but these numbers rely heavily on asterisks - like classifying AI model costs for free users as "R&D" instead of COGS.
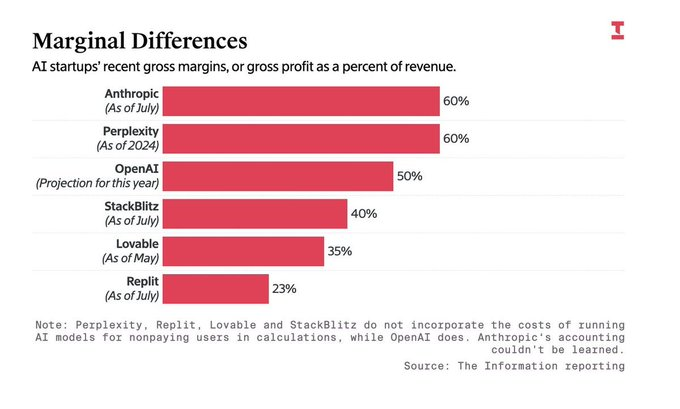
Source: The Information
Strip away the accounting magic, and you're left with the reality: these are low-margin businesses pretending to be high-margin software companies. They're selling compute below cost, hoping the economics will improve before reality catches up. Unless they are like Replit and a few others, selling a platform play with higher-margin business lines like hosting and domain purchases to subsidize compute, the math doesn't math.
In Episode II, we’ll do an over-engineered deep dive into the token economics behind AI code editing. We’ll reveal how a simple request to change a box shadow color balloons into thousands of tokens and dollars of compute and why the economics of compute don’t compute.